Deep learning has emerged as a potent tool in artificial intelligence, enabling breakthroughs in image recognition, natural language processing, and various other fields. Nevertheless, one significant hurdle that researchers face is the presence of label noise in training datasets. Label noise refers to incorrect or misleading labels that can impair the model’s ability to learn effectively. As a result, the performance of these models on unseen test datasets may suffer drastically. The implications are particularly dire in sensitive areas such as healthcare or autonomous driving, where accuracy is paramount.
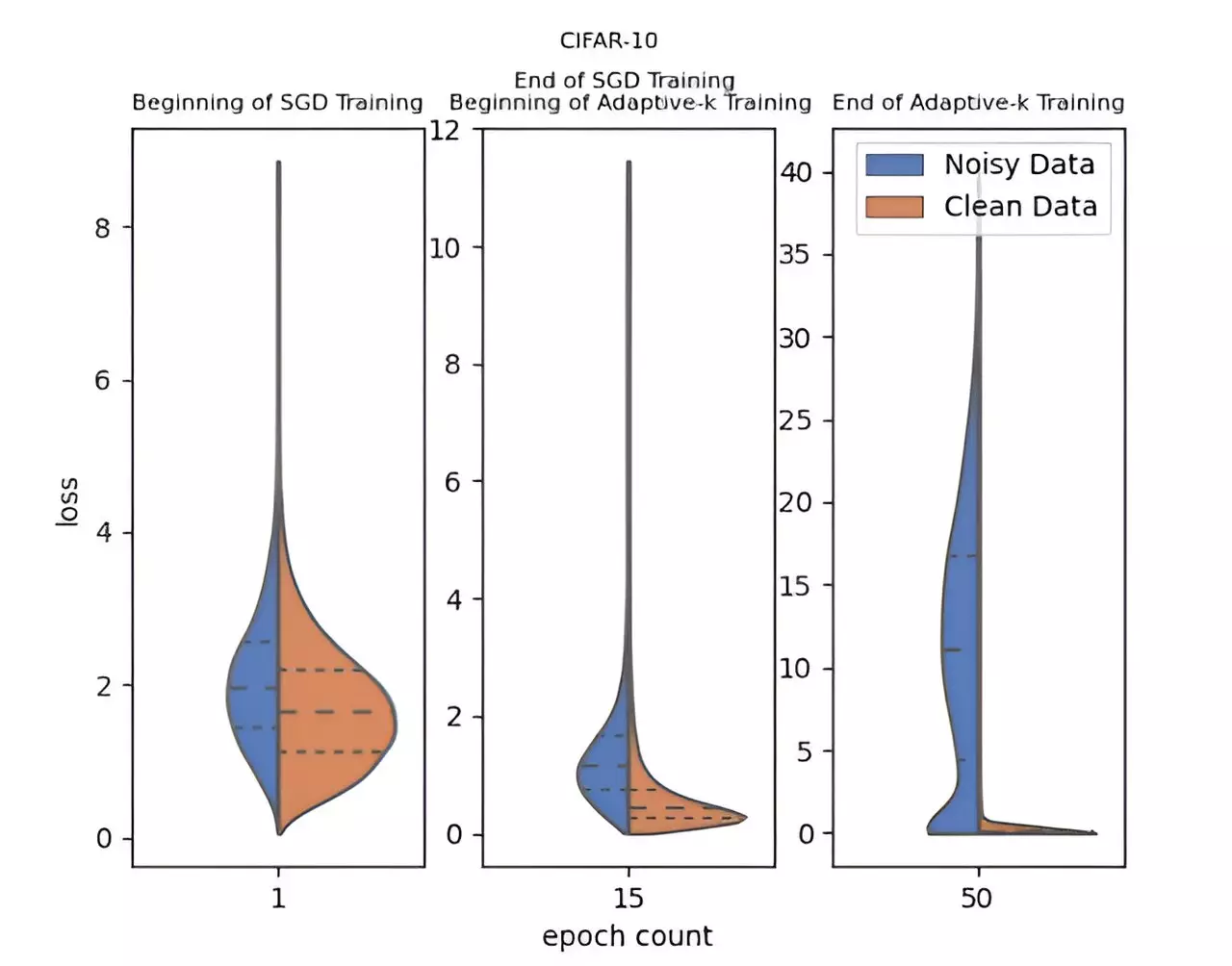
In response to this detrimental aspect of training, a team of researchers from Yildiz Technical University, including Enes Dedeoglu and H. Toprak Kesgin, spearheaded by Prof. Dr. M. Fatih Amasyali, has developed an innovative method called Adaptive-k. This advanced algorithm enhances the optimization process by adaptively determining the number of samples selected for each mini-batch update. This fine-tuned approach enables better differentiation between noisy and clean samples, ultimately boosting the effectiveness of training.
What makes Adaptive-k particularly noteworthy is its simplicity and efficiency. Unlike other methodologies, it does not demand comprehensive knowledge of the dataset’s noise ratio, additional model training complexities, or extended training durations. As a result, it stands out as an attractive option for researchers and practitioners alike.
The inventiveness of Adaptive-k is highlighted through its impressive performance in comparison to several established algorithms, including Vanilla, MKL (Multi Kernel Learning), and Trimloss. The research team engaged in rigorous experimental validation, utilizing three distinct image datasets and four text datasets to substantiate their claims. Astonishingly, Adaptive-k approached the performance outcomes of the ideal Oracle method, which operates under the condition that all noisy samples are removed from the dataset prior to training.
Such a feat not only demonstrates the method’s capabilities but also emphasizes the potential for widespread application across various domains. Its compatibility with popular optimization techniques such as Stochastic Gradient Descent (SGD), SGDM, and Adam strengthens its versatility.
Following the success of Adaptive-k, the research team aims to delve deeper into refining the method further, exploring new applications, and enhancing its performance in increasingly challenging noise environments. The anticipation surrounding Adaptive-k suggests that it could transform how researchers approach model training in noisy conditions, marking a significant advancement in the field of deep learning.
To conclude, the Adaptive-k method represents a pioneering step forward in addressing the pervasive problem of label noise in deep learning datasets. By providing a robust, efficient, and easy-to-implement solution, this innovative algorithm is set to improve classification performance dramatically and expand the horizons of deep learning applications across various sectors. Researchers and industry practitioners alike stand to benefit significantly from this groundbreaking development.
Leave a Reply